
原文来源:medium
作者:Abdellatif Abdelfattah
「机器人圈」编译:嗯~阿童木呀

我们将要构建一个可以用来识别图像的神经网络,其精确度可达到78.4%,与此同时,我们还将解释整个过程中使用的技术。
介绍
近期以来,深度学习在各个领域应用广泛,其取得的最近进展使得诸如图像和语音识别等任务成为可能,不再遥不可及。
深度学习:机器学习算法的一个子集,擅长于模式识别,但通常需要大量的数据。
深度学习在识别图像中的对象方面具有非常优异的表现,因为它是通过3层或更多层人工神经网络实现的,其中每层都负责提取图像的一个或多个特征(详情稍后介绍)。
神经网络:一种与人脑中神经元类似的计算模型。每个神经元接受一个输入,执行一些操作,然后将输出传递给下面的神经元。
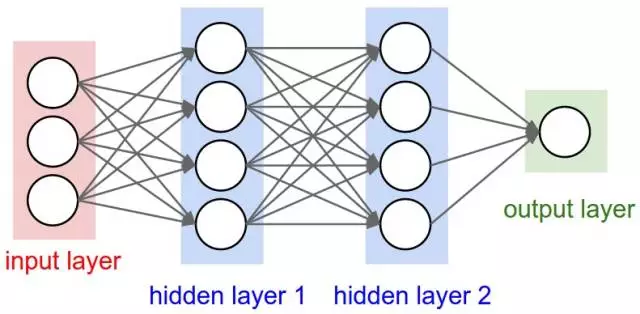
神经网络表征图(src)
我们将教计算机识别图像并将它们分类为以下10种类别中的一个类别:

为了实现这一目的,我们首先需要在计算机能够识别一个新对象之前教它认识猫,狗和鸟等对象。计算机看到的猫越多,其识别猫的能力就越好。这就是所谓的监督学习。我们可以通过标记图像来执行此任务,计算机将开始识别猫图片中出现的模式,而这些模式在其他图片中是不存在的,而后计算机将开始构建自己的认知。
我们将使用Python和TensorFlow来编写程序。TensorFlow是一个由Google创建的开源深度学习框架,它可以让开发者对每个神经元(在TensorFlow中被称为“节点”)进行细粒度控制(granular control),这样你就可以调整权重,实现最佳性能。TensorFlow有许多内置的库(其中很少是可以用于我们的图像分类任务中的),并有一个令人惊奇的社区,所以你将能够在其中找到几乎任何有关深度学习主题的开源实现。
那么我们就开始行动吧——教计算机进行图像分类!
用于图像分类的机器学习
计算机能够对数字进行计算,但无法以我们的方式来解读图像。因此我们必须以某种方式将图像转换为计算机能够理解的数字。
在图像处理中有两种常用的方法:
1.使用灰度级(Greyscale):
图像将被转换为灰度级(灰色范围从白色到黑色),计算机将根据颜色的深浅为每个像素分配一个值。所有的数字都将放在一个数组中,然后计算机将在该数组上进行计算。这是使用灰度级后所看到的数字8:
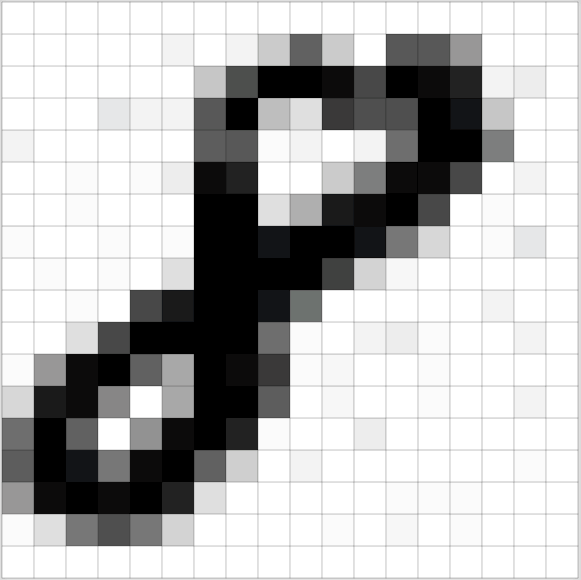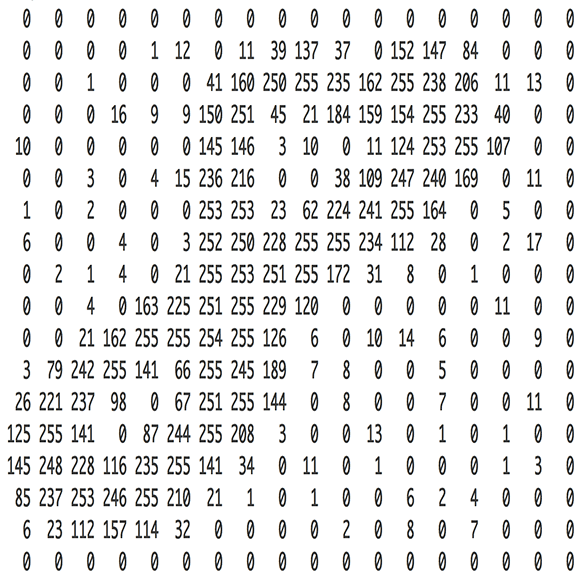
图像转换为数字(src)
然后我们将结果数组输入到计算机中:

结果数组(src)
2.使用RGB值:
颜色可以表示为RGB值(红色,绿色和蓝色的组合,范围从0到255)。然后,计算机可以提取每个像素的RGB值,并将结果放在数组中进行解读。
当计算机对一个新的图像进行解读时,它将使用相同的技术把图像转换为数组,继而将数字模式与已知对象进行比较。然后计算机将为每个类分配一个置信度分数。具有最高置信度分数的类通常就是计算机所预测的那一个。
CNN(卷积神经网络)
简而言之,在人工智能领域中,用于提高图像分类精确度的最流行技术之一就是卷积神经网络(简称CNN)。
卷积神经网络:一种特殊类型的神经网络,其工作方式与常规神经网络相同,只是开始时具有一个卷积层。
该技术不是将整个图像作为数字数组,而是将图像分解成多个图块,然后计算机会尝试预测每个图块是什么。最后,计算机试图根据所有图块的预测结果来分析预测图片中的对象。这使得计算机能够并行化操作并检测对象,而不管其位于图像中的位置。
数据集
我们决定使用CIFAR-10数据集,该数据集由60,000个尺寸为32 x 32像素的图像组成。该数据集包含10个相互排斥(不重叠)的类,每个类中含有6,000个图像。图像小巧,标记清晰,没有噪声,这些优点使得该数据集成为这项任务的理想选择,而且只需要非常少的预处理就可以了。以下是从数据集中获取的几张图片:
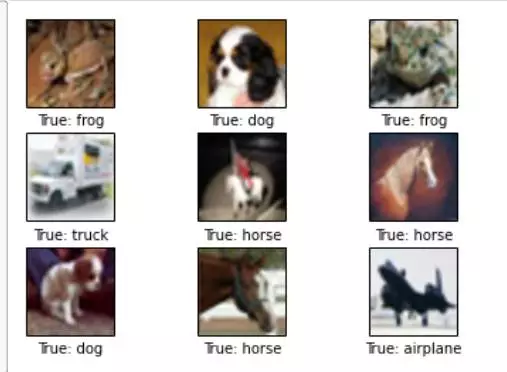
步骤1:预处理
首先,我们需要为数据添加一些变化,因为数据集中的图像是非常有组织的,并且几乎不包含任何噪声。我们将使用名为imgaug的Python库人为地添加噪声。接下来我们要对图像进行随机组合:
1.图像的裁剪部分
2.水平翻转图像
3.调整色调,对比度和饱和度
经过上述组合操作之后的图片外观效果
以下是用于图像预处理操作的Python代码:


步骤2:拆分我们的数据集
对于使用整个大型数据集的模型来说,计算其梯度需要花费很长时间。因此,我们将在优化器的每次迭代期间使用一小批图像。批量大小通常是32或64—我们将使用的是64,因为我们有相当多的图像。然后将数据集分为含有50,000张图像的训练集,以及包含10,000张图像的测试集。

步骤3:构建一个卷积神经网络
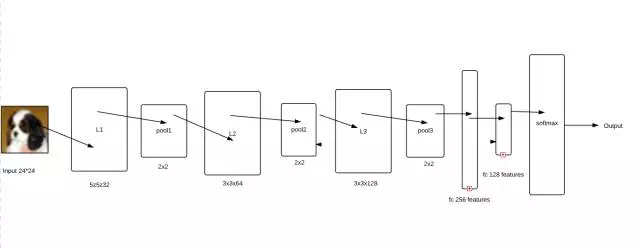
神经网络架构
现在我们已经完成了对数据集的预处理和拆分操作,那么,接下来我们可以开始实现神经网络。我们将要有3个具有2×2最大池化(max-pooling)的卷积层。
最大池化(max-pooling):一种通过获取网格的最大像素值来减小图像尺寸的技术。此外该技术还有助于减少过度拟合,使模型更为通用。以下示例显示了2 x 2 最大池化的工作原理:
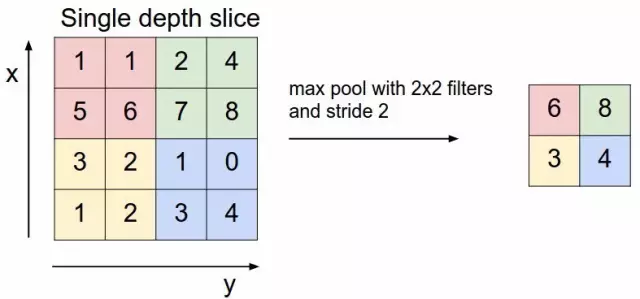
2 x 2最大池化(src)
之后,我们将添加2个完全连接层。由于完全连接层的输入应该是二维的,卷积层的输出是四维的,所以我们需要在它们之间有一个扁平层(flattening layer)。
在完全连接层的最末端是一个softmax层。
可是说参数识别是一项非常具有挑战性的任务,因为我们有如此多的参数需要调整。因此,我们阅读了大量的资料,并试图找出一种实现方法。但是,效果并不明显,因为它似乎需要大量的经验。所以我们发现了一个由Alex Krizhevsky搭建的架构,他使用这种结构,并赢得了ImageNet LSVRC-2010的冠军。而相较于他的工作任务,我们的任务就简单的多了,所以我们只使用3个卷积层,并在每个层之间保持一个梯度。
结果
既然我们已经有一个已训练的神经网络,那么我们就可以使用它来进行试验了!然后,我们让计算机解读10,000个未知图像,其达到的精度为78.4%(7844/10000)。有趣的是,不正确的预测看起来与计算机所认为的非常接近。

错误预测的样本
以右上方的图片为例,图片看起来就像一只坐在卡车上的猫,所以对于计算机来说,将其预测为卡车也是很合理的。
结论
以上就是对使用神经网络进行图像识别的详细介绍,总而言之,现如今,我们可以使用TensorFlow构建一个人工卷积神经网络,其识别图像的精确度为78%。我们要对图像进行预处理操作从而使其更为通用,然后将数据集拆分成多个批次,最后构建和训练模型,从而使其能够识别图像。
注:点击GitHub repo查看完整代码资源。返回搜狐,查看更多
责任编辑:

