
请点击此处输入图片描述
图:pixabay
原文来源:machine learning mastery
作者:Jason Brownlee
「机器人圈」编译:多啦A亮
神经网络诸如长短期记忆(LSTM)循环神经网络(RNN)能够几乎无缝地模拟多个输入变量的问题。
这是时间序列预测中的一大优点,而经典线性方法难以适应多变量或多输入预测问题。
在本教程中,你将发现如何在Keras深度学习库中开发多变量时间序列预测的LSTM模型。
完成本教程后,你将知道:
•如何将原始数据集转换为可用于时间序列预测的内容。
•如何准备数据并适应多变量时间序列预测问题的LSTM。
•如何做出预测并将结果重新调整到原始单位。
让我们开始吧。
教程概述
本教程分为3部分,他们是:
•空气污染预报
•基本数据准备
•多变量LSTM预测模型
Python环境
本教程假定你已安装Python SciPy环境。你可以在本教程中使用Python 2或3。
你必须使用TensorFlow或Theano后台安装Keras(2.0或更高版本)。
本教程还假定你已经安装了scikit-learn、Pandas、NumPy和Matplotlib。
如果你需要安装环境方面的帮助,请参阅这篇文章:
《如何用Anaconda设置机器学习和深度学习的Python环境》
空气污染预报
在本教程中,我们将使用空气质量数据集。
这是一个数据集,在美国驻北京的大使馆五年内每小时报告天气和污染水平。
数据包括日期时间, PM2.5污染物,以及天气信息,包括露点、温度、气压、风向、风速以及降雨和降雪的累积小时数。原始数据中的完整功能列表如下:
1.No: 行号
2.year: 这一行的一年数据
3.month: 这一行的月数据
4.day: d这一行的日数据
5.hour: 这一行的小时数据
6.pm2.5: PM2.5浓度
7.DEWP: 露点
8.TEMP: 温度
9.PRES:气压
10.cbwd: 组合风向
11.Iws: 累积风速
12.Is: 积雪时间
13.Ir: 累积的降雨时间
我们可以使用这些数据并构建一个预测问题,鉴于天气条件和前几个小时的污染,我们预测下一个小时的污染。
此数据集可用于构建其他预测问题。
你可以从UCI Machine Learning Repository下载数据集。
•北京PM2.5数据集
下载数据集并将其放在你当前的工作目录中,文件名为“raw.csv”。
基础数据准备
数据没还有准备好去使用。所以,我们必须先做好准备。
以下是原始数据集的前几行:

请点击此处输入图片描述
第一步是将日期时间信息整合到一个单独的日期时间,以便我们可以将其用作Pandas的索引。
快速检查显示前24小时pm2.5的NA值。 因此,我们需要删除第一行数据,在数据集中还有几个分散的“NA”值; 我们现在可以用0值标记它们。
以下脚本加载原始数据集,并将日期时间信息解析为Pandas DataFrame索引。No列被删除,然后为每列指定更清晰的名称。最后,将NA值替换为“0”值,并删除前24小时。
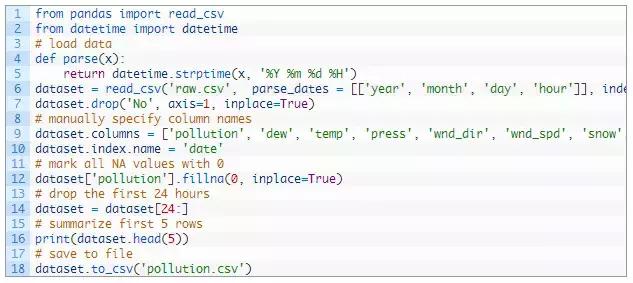
请点击此处输入图片描述
运行该示例打印转换后数据集的前5行,并将数据集保存到“pollution.csv”。

请点击此处输入图片描述
现在我们以简单易用的形式提供数据,我们可以创建每个系列的快速图,来看看我们得到的。
下面的代码加载了“pollution.csv”文件,并将每个系列作为单独的子图绘制,除了风速是分类的。

请点击此处输入图片描述
运行示例创建一个具有7个子图,显示每个变量的5年数据。
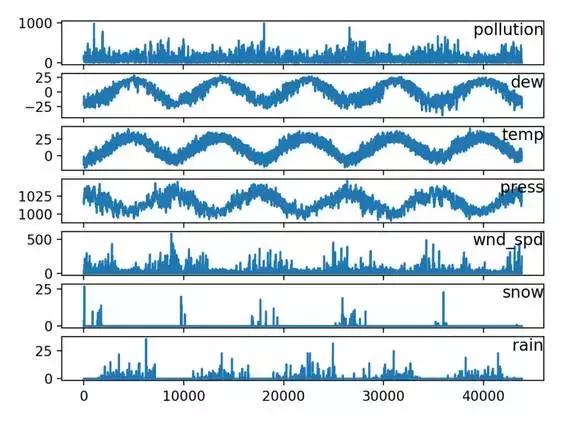
请点击此处输入图片描述
空气污染时间序列线图
多变量LSTM预测模型
在本节中,我们将使用LSTM解决问题。
LSTM数据准备
第一步是为LSTM准备污染数据集。
这涉及将数据集视为监督学习问题并对输入变量进行归一化。
考虑到上一个时间段的污染测量和天气条件,我们将把监督学习问题作为预测当前时刻(t)的污染情况。
这个构想是直接的,只是为了这个演示。你可以探索的一些替代方法包括:
•根据过去24小时的天气和污染情况,预测下一个小时的污染。
•预测下一个小时的污染,并给予下一个小时的“预期”天气条件。
我们可以使用在下列文章中开发的series_to_supervised()函数来转换数据集:
•如何将时间序列转换为Python中的监督学习问题。
首先,加载“pollution.csv”数据集。风速特征是标签编码(整数编码)。如果你有兴趣探索,这可能会在将来进一步被热编码。
其次,所有功能都被归一化,然后将数据集转换为监督学习问题。然后删除要预测的小时的天气变量(t)。
完整的代码清单如下:
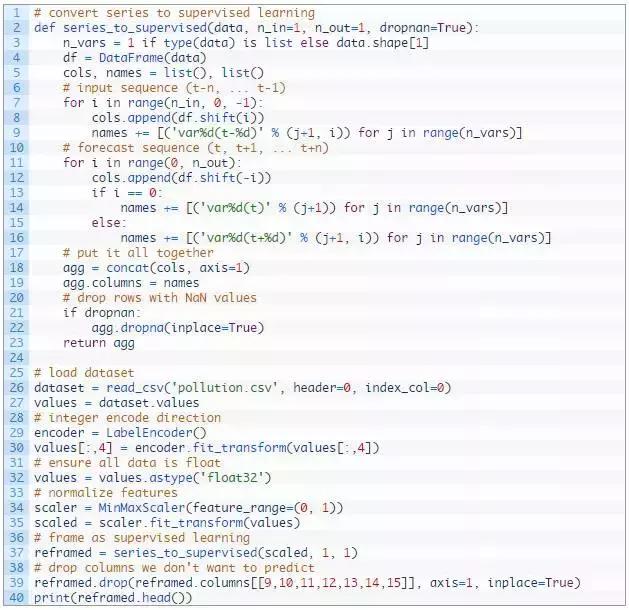
请点击此处输入图片描述
运行示例打印转换后的数据集的前5行。我们可以看到8个输入变量(输入序列)和1个输出变量(当前小时的污染水平)。

请点击此处输入图片描述
这个数据准备很简单,我们可以探索更多的东西。你可以看到的一些想法包括:
•独热编码风速。
•通过差分和季节性调整使所有系列固定。
•提供超过1小时的输入时间步长。
最后一点可能是最重要的,因为在学习序列预测问题时,LSTMs通过时间使用反向传播。
定义和拟合模型
在本节中,我们使用多变量输入数据的LSTM。
首先,我们必须将准备好的数据集分成训练集和测试集。为了加快对这次示范的训练速度,我们将仅适用于数据第一年的模型,然后对其余4年的数据进行评估。如果你有时间,请考虑浏览此测试工具的倒置版本。
下面的示例将数据集分成训练集和测试集,然后将训练集和测试集分成输入和输出变量。 最后,将输入(X)重构为LSTM预期的3D格式,即[样本,时间步长,特征。
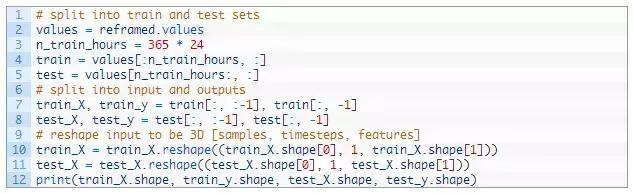
请点击此处输入图片描述
运行此示例打印训练集的形状,并测试输入和输出集合约9000小时的数据进行训练,约35000小时的数据进行测试。
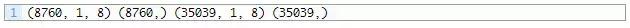
请点击此处输入图片描述
现在我们可以定义并配置LSTM模型
我们将在第一个隐藏层中定义具有50个神经元的LSTM以及输出层中用于预测污染的的1个神经元。输入形式将是一个时间具有8个特征的步长,。
我们将使用平均绝对误差(MAE)损失函数和随机梯度下降的高效Adam版本。
该模型将配置为适用于50个批量大小为72的训练周期。请记住,每个批处理结束时,Keras中的LSTM的内部状态都将重置,因此一个内部状态是一个有关大量天数的函数将会有所帮助。(不妨试一试)。
最后,我们通过在fit()函数中设置validation_data参数来跟踪训练过程中的训练和测试损失,然后在运行结束时,绘制训练和测试损失曲线图。
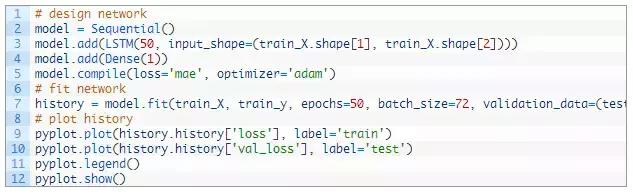
请点击此处输入图片描述
评估模型
当模型配置好之后,我们可以对整个测试数据集进行预测。
我们将预测与测试数据集相结合,并进行反缩放,我们还用预期的污染数据对测试数据集进行反缩放。
以预测值和实际值为原始尺度,我们可以计算模型的误差值。在这种情况下,我们计算出在与变量本身相同的单位中产生误差的均方根误差(RMSE)。
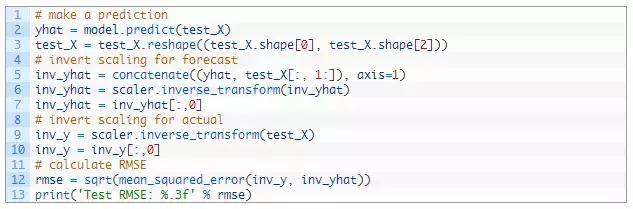
请点击此处输入图片描述
完整示例
完整的示例如下所示:
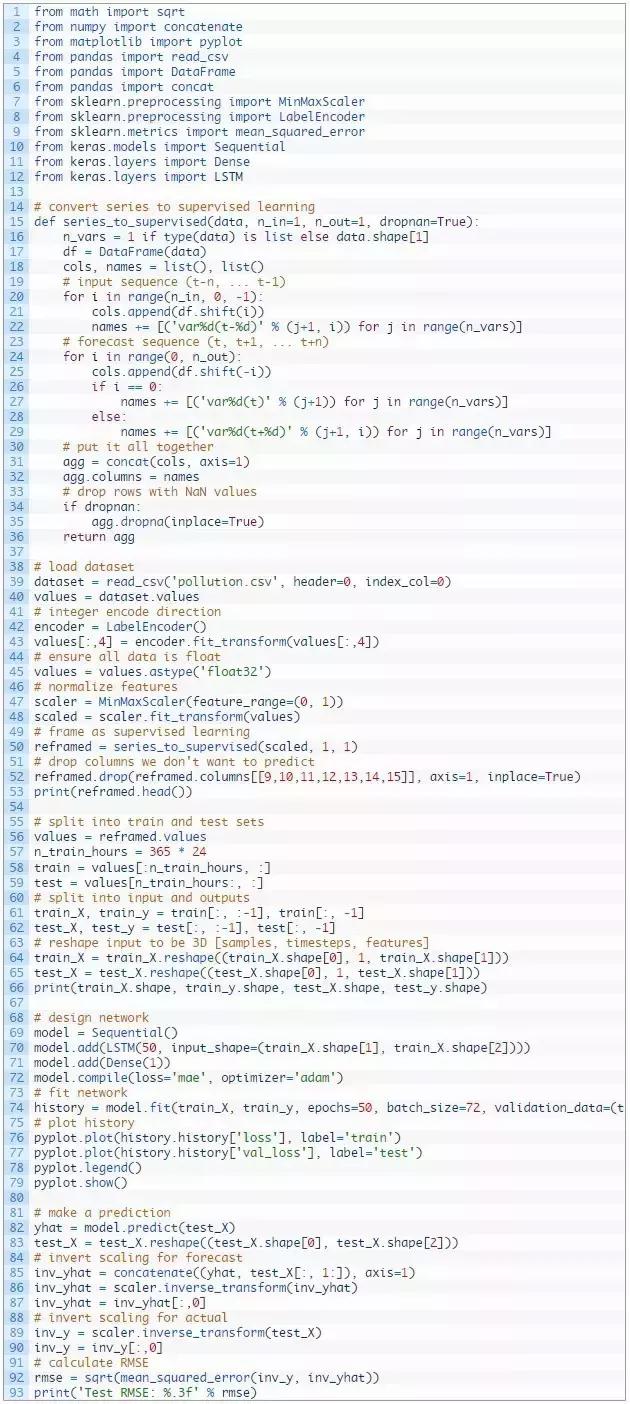
请点击此处输入图片描述
想要运行示例的话,首先需要创建一个绘图,显示训练期间的训练和测试损失。
有趣的是,我们可以看到测试损失低于训练损失。该模型可能过度拟合训练数据。在训练过程中测量和绘制RMSE曲线可能会使这一点显现得更加明显。

请点击此处输入图片描述
训练期间多元LSTM的训练集和测试线路图
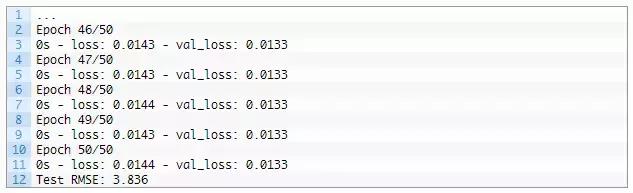
训练和测试损失在每个训练时期结束时都会打印出来。在运行结束时,打印测试数据集上模型的最终RMSE。
我们可以看到,该模型实现了3.836的可观RMSE,这显著低于用持续模型发现的30 RMSE。
请点击此处输入图片描述
进一步阅读
如果你想进一步深入了解,本部分将提供更多关于该主题的资源。
•在UCI机器学习库中的北京PM2.5数据集。
•Keras长短期记忆模型的5步生命周期。
•使用Python中的长短期记忆模型进行时间序列预测。
•用Python中的长短期记忆模型进行多步时间序列预测。
总结
在本教程中,你发现了如何将LSTM适用于多变量时间序列预测问题。
具体来说,通过本教程你将学到:
•如何将原始数据集转换为可用于时间序列预测的内容。
•如何准备数据并配置用于多变量时间序列预测问题的LSTM。
•如何做出预测并将结果重新调整到原始单元中。返回搜狐,查看更多
责任编辑:

