众所周知,在实验中我们会遇到各种各样的数据,那么想象一下,如果我们遇到没有标签的数据会发生什么呢?大多数深度学习技术需要干净的标注数据,但这一点现实吗?从技术本质上说,如果你有一组输入及其各自的目标标签,你可以试着去了解特定目标的特定标签概率。当然,现实中图像映射真的会如此美好吗?在这篇文章中,我将探索变分自编码器(VAE),以更深入了解未标记数据的世界。该模型在对没有标签的图像集合进行训练后将产生独特的图像。
自动编码器将输入数据顺序地解构为隐藏表示,并使用这些表示来顺序地重构与它们的原始内容相似的输出。它本质上是数据特定的数据压缩,而这意味着它只能对类似于已经它训练的数据进行压缩。当然,自动编码器也被公认为是有损耗的,因此相较于原始输入,解压缩输出结果会稍微降低一些。那么大家可能会有所疑问,如果它们会造成质量损失,为什么还那么实用呢?这是一个很好的问题,事实证明,它们对于数据去噪是非常有用的,即我们在这里训练一个自动编码器,从自身损坏版本中重构输入,这样它就可以消除类似的损坏数据。
首先,我们来谈谈贝叶斯推理(Bayesian inference)。所有阅读这篇文章的人可能都知道深度学习,以及谈到近似复杂函数时它的有效性,然而贝叶斯推理提供了一个独特的框架来解释不确定性,所有的不确定性都是用概率表示的。这是有道理的,如果你仔细想想,在任何给定的时间,都有证据支持或反对我们已知的事物,这些证据可以被用来创造一个新的概率。再进一步,当我们学习新的东西时,我们必须考虑我们已经知道的,并将新的证据加入到考虑范围内,创造一个新的概率。贝叶斯理论基本上是用数学方法描述这个概念的。
VAE就是这些想法的产物。从贝叶斯的角度来看,我们可以将VAE的输入、隐藏表示和重构输出视为有向图形模型中的概率随机变量。假设它包含一些数据的特定概率模型,x和潜在/隐藏变量z,我们便可以写出模型的联合概率,如下所示:

模型的联合概率
给定模型生成的一个字符,我们不知道隐形变量的设置是如何生成这个字符的,我们的模型本质上就是随机的!
VAE由3个主要部分组成:
•编码器
•解码器
•损失函数
给定输入x,假设我们有一个28×28的手写数字图像,它可以达到784维度,其中每个像素都是一维的。现在,这将会编码到一个潜在/隐藏的表示空间,而这将要比784少很多。我们现在可以采样高斯概率密度来获得表示的噪声值。
是不是很酷?下面我们就用代码来将这个表示出来吧。(文章结尾将给出完整代码资源链接)
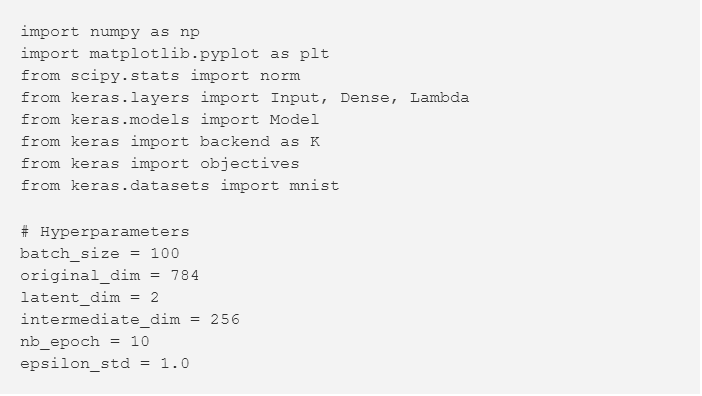
首先,我们导入库并找到我们的超参数。
接下来,初始化编码器网络。该网络的工作是将输入映射到隐藏的分布参数中。我们接受输入,并通过ReLU(压缩维度的经典非线性激活函数)的密集完全连接层发送它。下一步,我们将输入数据转换为隐藏空间中的两个参数。我们使用密集,完全连接层 - z mean和z log sigma来预定义大小。
解码器将“z”作为其输入,并将参数输出到数据的概率分布中。我们假设每个像素是1或0(黑色或白色),现在我们可以使用伯努利分布,因为它会将“成功”定义为二进制值来表示单个像素。因此,解码器将获得一个数字的潜在/隐藏表示以作为其输入,并且它会输出784个伯努利参数,每个像素一个,所以在0和1之间有784个值。
我们将使用z_mean和z_log_var,通过定义采样函数,从隐藏/潜在正态分布中随机抽取新的类似点。以下代码块中的epsilon是一个随机正态张量。

一旦我们得到z,我们可以将其提供给我们的解码器,解码器会将这些潜在空间点映射回原始输入数据。因此,为了构建一个解码器,我们首先用两个完全连接层及其它们各自的激活函数对其进行初始化。因为数据是从一个小的维度提取到一个较大维数,所以其中一些会在重构过程中丢失。
确实很酷?但是这个“一些”到底是多少呢?为了获取准确值,我们将建立损失函数对其进行精确测量。下面的第一项是测量重构损失。如果解码器 输出在重建数据方面很糟糕,那么损失方面的成本就会相当大。下一个项是正则化项,意味着它可以保持每个数字的表示尽可能多样化。所以举个例子来说就是,如果两个不同的人同时写出数字3,那么这些表示结果可能会看起来很不一样,因为不同的人写的结果当然会不一样。这可能是一个不尽如人意的结果,而正则化项的任务就是拯救“不如意”!我们对不良行为进行惩罚(如这里的例子),并确保类似的表示是紧密相连的。我们可以将总损失函数定义为重构项和KL的散度正则化项的总和。
现在来到训练部分,我们通常会使用梯度下降来训练这个模型,以优化我们对编码器和解码器参数的损失。但是我们如何对随机确定的变量的参数进行衍生?
原来,我们已经将随机性建立在我们的模型本身上了。现在,梯度下降通常期望一个给定的输入总是返回一个固定参数组的相同输出。在我们这种情况下唯一的随机来源将是输入。那么我们如何解决这个问题呢?我们重新确定参数!我们将对样本进行重新确定参数,使得随机性可以独立于参数。
我们将定义一个取决于参数确定性的函数,因此我们可以通过引入随机变量将随机性注入到模型中。编码器将生成平均值向量和标准偏差向量,而不是生成实数值的向量。我们采用涉及z的函数关于其分布参数的导数。我们将模型的优化器定义为rmsprop,并将损失函数定义为vae_loss。
我们通过导入MNIST数据集并将它们馈送到我们的模型中,为给定数量的训练次数和批量大小开始下面的训练。

下面我们画出二维平面上的邻域。每个颜色聚类用一个数字表示,而闭合聚类本质上是与结构相似的数字。

数字表示法
另一种表示方法是通过扫描潜在计划(latent plan)生成数字,定期采样潜点,并为这些点生成相应的数字,如下所示:



生成的数字
这在某些程度上让你感到震撼!
所以这个练习在本质上有三个关键的要点:
•变分编码器允许我们通过执行无监督学习以生成数据。
•VAE =贝叶斯推理+深度学习。
•重参数化使我们能够通过网络进行反向传播,随机独立的参数使我们能够得出梯度。资源:https://github.com/vvkv/Variational-Auto-Encoders/blob/master/Variational%2BAuto%2BEncoders.ipynb返回搜狐,查看更多
责任编辑:

