
图:pixabay
原文来源:machinelearningmastery
作者:Jason Brownlee
「机器人圈」编译:嗯~阿童木呀、多啦A亮
不知道在训练模型的过程中,你有没有遇到这样一个问题,很难确定你的长短期记忆网络模型是否在序列问题上表现良好。
也许在模型技能上你会获得一个不错的分数,但是更为重要的是,要知道你的模型是否与你的数据拟合良好,或者欠拟合,或者过度拟合,以及是否能够在不同的配置中做得更好。
在本教程中,你将知晓如何诊断LSTM模型在序列预测问题上的拟合问题。
完成本教程后,你将学会:
如何收集和绘制LSTM模型的训练历史。
如何诊断一个欠拟合、拟合和过度拟合模型。
如何通过平均多模型运行来开发更具鲁棒性的诊断。
那接下来就开启我们的探索之旅吧。
教程概述
本教程共分为6部分,它们分别是:
用Keras进行的训练史
诊断图
欠拟合范例
拟合良好范例
过度拟合范例
多次运行范例
1.用Keras进行的训练史
你可以通过回顾它在过去时间里的性能情况来了解模型行为。
通过调用fit()函数训练LSTM模型。此函数返回一个名为history的变量,其中包含损失追踪以及在编译模型时指定的任何其他指标。这些分数都记录在每个训练轮数的末尾。
...
history = model.fit(...)
例如,如果你的模型被编译为优化日志丢失(binary_crossentropy)并且测量每个训练轮数的精确度,那么会将损失和精确度记录在每个训练轮数的历史轨迹中。
通过调用fit()函数返回的历史对象中的一个键即可访问每个评分。默认情况下,在拟合模型过程中优化的损耗称为“loss”,精确度称为“acc”。
...
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100)
print(history.history['loss'])
print(history.history['acc'])
在拟合模型的过程中,Keras允许你指定一个单独的验证数据集,同时也可以使用相同的损失和指标进行评估。
这可以通过在fit()上设置validation_split参数,从而将训练数据的一部分用作验证数据集来实现。
...
history = model.fit(X, Y, epochs=100, validation_split=0.33)
这也可以通过设置validation_data参数并传递一个X和y数据集的元组来完成。
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
在验证数据集上评估的指标可以通过使用相同的名称键入,即“val_”前缀。
...
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100, validation_split=0.33)
print(history.history['loss'])
print(history.history['acc'])
print(history.history['val_loss'])
print(history.history['val_acc'])
2.诊断图
关于LSTM模型的训练史可用于诊断模型的行为。
你可以使用Matplotlib库绘制模型的性能图。 例如,你可以绘制如下训练损失VS测试损失图:
from matplotlib import pyplot
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
创建并回顾这些图可以帮助你知晓那些可能的新配置,以便从模型中获得更好的性能。
接下来,我们将查看一些范例。 我们将根据损失最小化来考虑训练和验证集上的模型技能。当然,你可以使用对你的问题有意义的任何指标。
3.欠拟合范例
什么是欠拟合?所谓欠拟合就是说,一个在训练数据集上表现良好,但在测试数据集上表现不佳的模型。
这可以从一个训练损失低于验证损失的绘制图中得以诊断,且验证损失具有表明进一步改进有可能实现的趋势。
下面提供了一个小巧的欠拟合LSTM模型的例子。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=100, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行这个例子将产生一个训练和验证损失的绘制图,显示了一个欠拟合模型的特征。在这种情况下,通过增加训练轮数的数量可以提高性能。
在这种情况下,通过增加训练时期的数量可以提高性能。
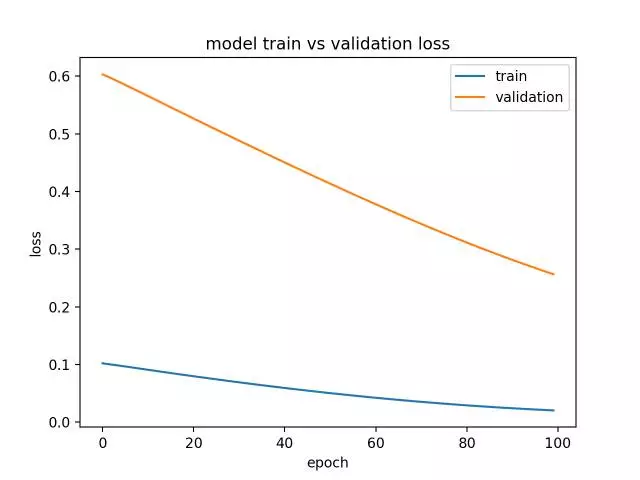
诊断线图显示了一个欠拟合模型
或者,如果训练集上的性能优于验证集并且性能已经下降,那么该模型也有可能是一个欠拟合模型。下面是一个没有足够记忆单元的欠拟合示例。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(1, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mae', optimizer='sgd')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行此示例显示出一个未能充分配置的模型的特征。
在这种情况下,可以通过增加模型的容量来提高性能,例如隐藏层中的记忆单元的数量或隐藏层的数量。
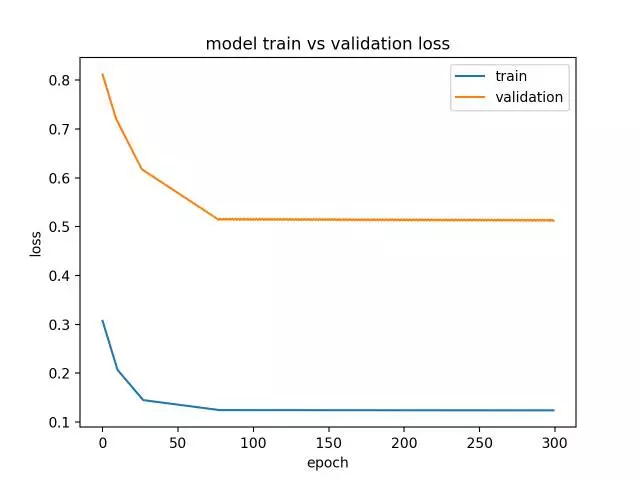
诊断线图通过状态显示了一个欠拟合模型
4.拟合示例
一个很好的拟合是指在训练和验证集上模型的性能都表现得很好。
这可以从训练和验证损失减少并在同一点稳定的情况下诊断。
下面的小例子演示了LSTM模型具有良好的拟合。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=800, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行示例创建一个显示训练和验证损失相遇的线条图。
理想情况下,如果可能的话,我们希望看到这样的模型性能,尽管这可能不适用于具有大量数据的有挑战性的问题。
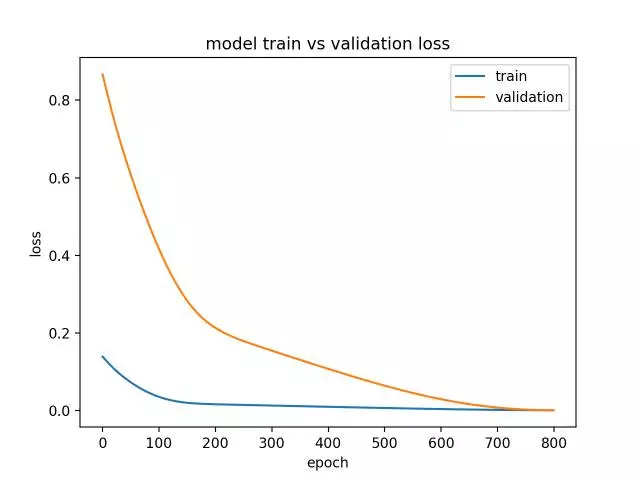
诊断线图显示一个很好的拟合模型
5.过度拟合示例
过度拟合模型是一个在训练上的性能良好并持续改进的模型,而验证集上的性能提升到一个点,然后开始降级。
这可以从训练损耗向下倾斜和验证损失向下倾斜的曲线中诊断出来,碰到拐点,并再次开始向上倾斜。
下面的例子演示了一个LSTM过度拟合模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=1200, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'][500:])
pyplot.plot(history.history['val_loss'][500:])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行此示例创建一个绘图,显示过度模型验证损失中的特征拐点。
这可能是训练次数太多的特征。
在这种情况下,模型训练可以在拐点处停止。或者,可以增加训练示例的数量。
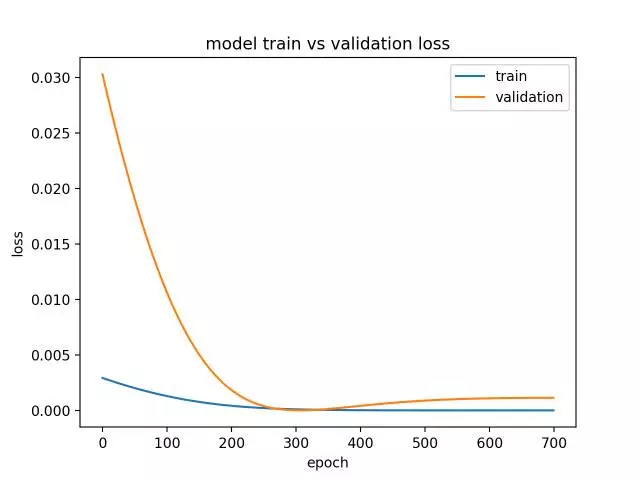
诊断线图显示过度拟合模型
6.多次运行示例
LSTM是随机的,这意味着每次运行你会得到一个不同的诊断图。
重复诊断运行多次(例如5次,10次或30次)可能是有用的。然后,可以绘制每个运行的训练和验证轨迹,以便随着时间的推移对模型的行为提供更具有鲁棒性的想法。
以下示例运行多次相同的实验,然后绘制每次运行的训练轨迹和验证损失。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
from pandas import DataFrame
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# collect data across multiple repeats
train = DataFrame()
val = DataFrame()
for i in range(5):
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
X,y = get_train()
valX, valY = get_val()
# fit model
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# story history
train[str(i)] = history.history['loss']
val[str(i)] = history.history['val_loss']
# plot train and validation loss across multiple runs
pyplot.plot(train, color='blue', label='train')
pyplot.plot(val, color='orange', label='validation')
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.show()
在生成的结果图中,我们可以看到,五次运行的总体趋势是持续不断的,也许增加了训练轮数的数量。
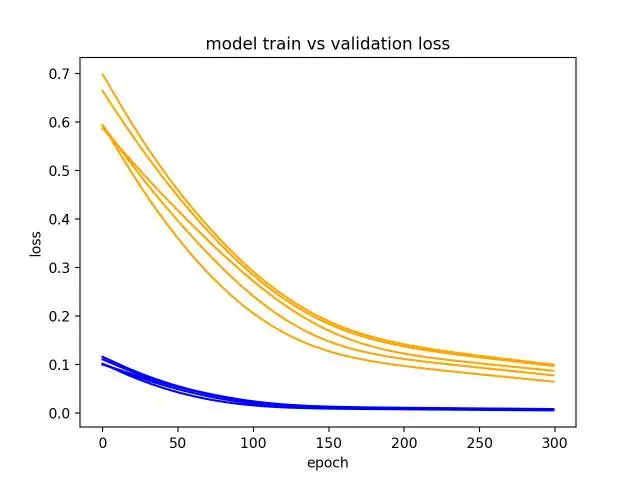
诊断线图显示模型的多个运行
进一步阅读
如果你进一步了解,本部分将提供有关该主题的更多资源。
•Keras API回调函数的历史(https://keras.io/callbacks/#history)
•维基百科上机器学习中的学习曲线(https://en.wikipedia.org/wiki/Learning_curve#In_machine_learning)
•在维基百科上的过度拟合(https://en.wikipedia.org/wiki/Overfitting)返回搜狐,查看更多
责任编辑:

