用Python爬取网易云音乐用户评论数据源码:
https://github.com/zerohd4869/163mc_spider
本文利用Python2.7根据网易云音乐歌曲ID爬取了该歌曲的所有用户评论数据。以id是28875120的歌曲《小岁月太着急》为示例,通过Chrome的DevTools工具获取已加密评论数据,然后基于AES对称加密算法对已加密数据进行解密实现,最后使用Python成功实现了对用户评论数据的抓取与保存。
利用DevTools工具获取加密数据
进入 http://music.163.com/#/song?id=28875120 页面,打开Chrome的DevTools工具选择Network并重载页面,找到与评论数据相关的请求即name为R_SO_4_28875120?csrf_token=90e04572eb42b040167323ec2fcdd79f的POST请求,如下图所示:
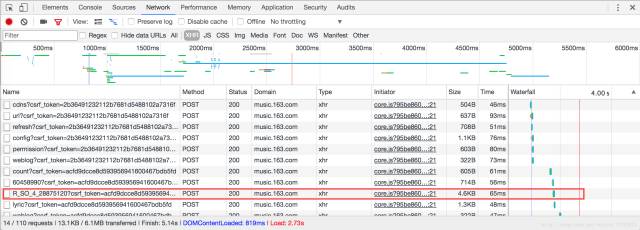
查看该请求信息,可知Request Headers参数如下:
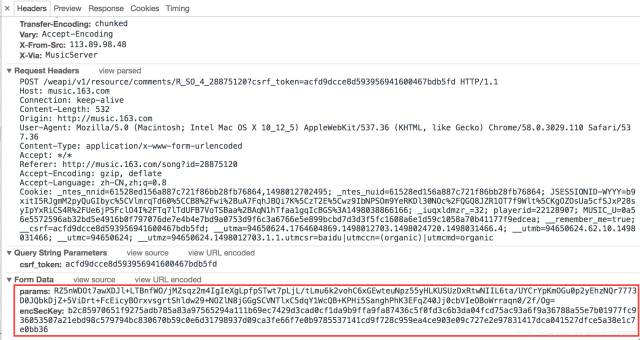
其中的POST Request URL完整地址为 :
http://music.163.com/weapi/v1/resource/comments/R_SO_4_28875120?csrf_token=90e04572eb42b040167323ec2fcdd79f
并且,该Form Data含有params和encSecKey两个参数,显然,这两个参数是经过js加密后的。服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),同时,通过查看第一张图可知该请求的Initiator为core.js,因此需要通过查看该js源码来分析两个参数的值。
根据源代码分析加密数据
AES加密算法分析
AES(Advanced Encryption Standard)对称加密算法是一种高级数据加密标准,可有效抵制针对DES的攻击算法。特点:密钥建立时间短、灵敏性好、内存需求低、安全性高。
将core.js文件clone到本地并对其格式化,发现params和encSecKey两个参数同时出现在以下代码中:
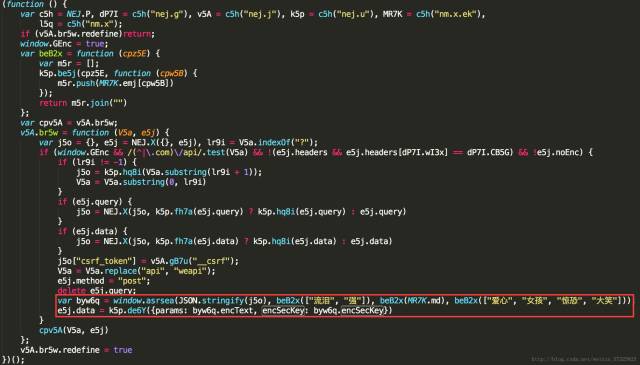
params的值为byw6q.encText,encSecKey的值为byw6q.encSecKey,而byw6q是由window.asrsea()这个函数得到,定位这个函数发现他其实是d(d, e, f, g)函数,该d函数代码如下图所示:
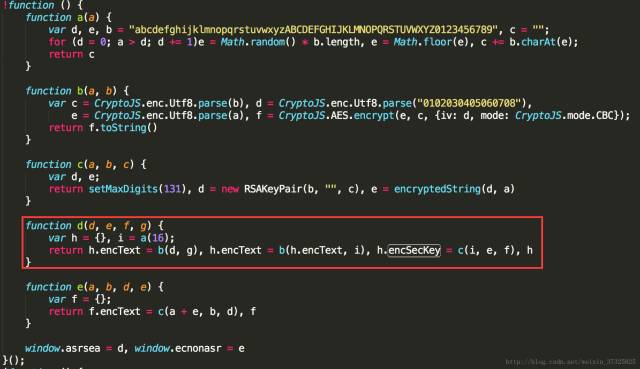
由代码可知,d函数对json格式的明文数据params调用了两次AES对称加密(即b函数):第一次对params的值d加密,key是第四个参数g,第二次对第一次加密结果h.encText值进行加密并更新encText值,key是长度为16的随机字符串i(不妨设其值为16个F)。而且,在b加密函数中,密钥偏移量iv值为”0102030405060708”,密码工作模式model值为CBC,即密文链接分组密码工作模式(明文加密前需要先和前面的密文进行异或运算,也就是相同的明文加密后产生不同的密文)。而d函数的第一个参数JSON.stringify(j5o)的值由j5o决定,在不同的请求下随着j5o的变化会有不同的值,而后面的三个参数均为定值。
获取 params值的代码如下:
# 第二个参数
second_param = "010001"
# 第三个参数
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b
5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f561
35fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46
bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc
6935b3ece0462db0a22b8e7"
# 第四个参数
forth_param = "0CoJUm6Qyw8W8jud"
def get_params(page): # page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1):
# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page- 1)* 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}'
%(offset, 'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
encSecKey的值由c(i, e, f)函数,其参数均为常数,因此无论歌曲id或评论页数如何变化,该值均不变。获取encSecKey值的代码如下:
defget_encSecKey():encSecKey = "257348aecb5e556c066de214e531faadd1c55d
814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02
ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a
9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f6
24750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"returnencSecKey AES解密算法实现
这里用到的AES算法为AES-128-CBC,密钥偏移量iv值为”0102030405060708”,分组密码填充方式为PKCS5Padding(即需对待加解密块按需补位),输出格式为base64。对称算法中加密与解密实现一致,代码如下:
defAES_encrypt(text, key, iv):pad = 16- len(text) % 16text = text + pad * chr(pad) encryptor = AES.new(key, AES.MODE_CBC, iv) encrypt_text = encryptor.encrypt(text) encrypt_text = base64.b64encode(encrypt_text)
returnencrypt_text
使用Python抓取评论数据抓取评论数据
获取json格式的评论数据的代码如下:
# 设置代理服务器proxies= {
'http:': 'http://121.232.146.184',
'https:': 'https://144.255.48.197'} defget_json(url, params, encSecKey):data = {
"params": params,
"encSecKey": encSecKey } response = requests.post(url,
headers=headers, data=data,proxies = proxies)
returnresponse.content
抓取热门评论的代码如下:
defget_hot_comments(url):hot_comments_list = [] hot_comments_list.append( u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数
评论内容n") params = get_params( 1) # 第一页encSecKey = get_encSecKey() json_text = get_json(url,params,encSecKey) json_dict = json.loads(json_text) hot_comments = json_dict[ 'hotComments'] # 热门评论print( "共有%d条热门评论!"% len(hot_comments))
foritem inhot_comments: comment = item[ 'content'] # 评论内容likedCount = item[ 'likedCount'] # 点赞总数comment_time = item[ 'time'] # 评论时间(时间戳)userID = item[ 'user'][ 'userID'] # 评论者idnickname = item[ 'user'][ 'nickname'] # 昵称avatarUrl = item[ 'user'][ 'avatarUrl'] # 头像地址comment_info = userID + " "+ nickname + " "+ avatarUrl + " "+
comment_time + " "+ likedCount + " "+ comment + u"n"hot_comments_list.append(comment_info)
returnhot_comments_list
抓取全部评论的代码如下:
defget_all_comments(url):all_comments_list = [] # 存放所有评论all_comments_list.append( u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容n") # 头部信息params = get_params( 1) encSecKey = get_encSecKey() json_text = get_json(url,params,encSecKey) json_dict = json.loads(json_text) comments_num = int(json_dict[ 'total']) if(comments_num % 20== 0): page = comments_num / 20else: page = int(comments_num / 20) + 1print( "共有%d页评论!"% page) fori inrange(page): # 逐页抓取params = get_params(i+ 1) encSecKey = get_encSecKey() json_text = get_json(url,params,encSecKey) json_dict = json.loads(json_text) ifi == 0: print( "共有%d条评论!"% comments_num) # 全部评论总数foritem injson_dict[ 'comments']: comment = item[ 'content'] # 评论内容likedCount = item[ 'likedCount'] # 点赞总数comment_time = item[ 'time'] # 评论时间(时间戳)userID = item[ 'user'][ 'userId'] # 评论者idnickname = item[ 'user'][ 'nickname'] # 昵称avatarUrl = item[ 'user'][ 'avatarUrl'] # 头像地址comment_info = unicode(userID) + u" "+ nickname + u" "+ avatarUrl + u" "+ unicode(comment_time) + u" "+ unicode(likedCount) + u" "+ comment + u"n"all_comments_list.append(comment_info) print( "第%d页抓取完毕!"% (i+ 1)) returnall_comments_list
将已获得的评论数据写入文本文件,代码如下:
defsave_to_file(list,filename):withcodecs.open(filename, 'a',encoding= 'utf-8') asf: f.writelines(list) print( "写入文件成功!")
利用Python获得数据结果获取Headers数据
获取headers代码如下:
headers = { 'Accept': "*/*", 'Accept-Encoding': "gzip, deflate",
'Accept-Language': "zh-CN,zh;q=0.8", 'Connection': "keep-alive",
'Content-Length': "416", 'Content-Type': "application/x-www-form-urlencoded", 'Cookie': "_ntes_nnid=61528ed156a887c721f86bb28fb76864,1498012702495; ...; __csrf=880488a01f19e0b9f25a81842477c87b", 'Host': "music.163.com", 'Origin': "http://music.163.com", 'Referer': "http://music.163.com/", 'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}
安装pycrypto
#pip uninstall Crypto#pip uninstall pycryptopip install pycrypto
抓取数据
#!/usr/bin/env python2.7# 、
-*- coding: utf-8 -*-
fromCrypto.Cipher
importAES importbase64
importrequests
importjson importcodecs importtime
if__name__ == "__main__": start_time = time.time() # 开始时间url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_28875120?csrf_token=90e04572eb42b040167323ec2fcdd79f"filename = u"小岁月太着急.txt"all_comments_list = get_all_comments(url) save_to_file(all_comments_list,filename) end_time = time.time() #结束时间print( "程序耗时%f秒."% (end_time - start_time))
1
数据结果输出
代码实现
ZerodeMBP:~ zero$ cd /Users/zero/Documents/ 163mc_spiderZerodeMBP: 163mc_spider zero$ python 163mc_spider.py共有 22页评论!共有 434条评论!第 1页抓取完毕!第 2页抓取完毕!...第 22页抓取完毕!写入文件成功!程序耗时 3.193853秒.
评论数据查看

http://blog.csdn.net/weixin_37325825/article/details/73556908
;返回搜狐,查看更多
责任编辑:

