随着人工智能技术的发展,机器翻译已经取得了很大进步。然而在传统方法中,需要数百万字的逐句对照来教会机器如何翻译。研究人员在新论文中表示,不需要平行文本,也可以学会翻译。
人类一直渴望沟通,早在 20 世纪 30 年代初,法国科学家 G.B. 阿尔楚尼提出了用机器来进行翻译的想法。经过几十年的努力,人类终于逐渐学会用机器翻译。用机器学习翻译经历了很多阶段:
起初是基于规则的翻译。最简单的翻译方法是逐字翻译。如「我爱你」翻译成「I love you」。随着句子越来越复杂,语言学家们发现了越来越多的规则,用程序实现。
下一个阶段是用统计方法进行翻译。专家把一句话分成块,把每一块所有可能的翻译都找到,选择几率最大的。最后将所有的句子生成,找到最有可能的。如「我爱你」,可能被翻译成「I love you」、「I like you」……最终「I love you」最适合,被系统选择。
建造这样一个系统需要大量的数据用于训练系统,我们需要平行文本,并至少被翻译成两种语言。但每当有一种新的语言,都需要专业人士进行调试和修整。
随着技术的发展,科学家发明了人工智能神经网络技术来翻译。以谷歌为例,他的翻译系统非常强大,需要很多训练数据和计算资源才能实现,它使用了序列到序列技术(sequence to sequence)。这个技术的翻译准确率已经超过了使用统计方法的机器翻译系统。
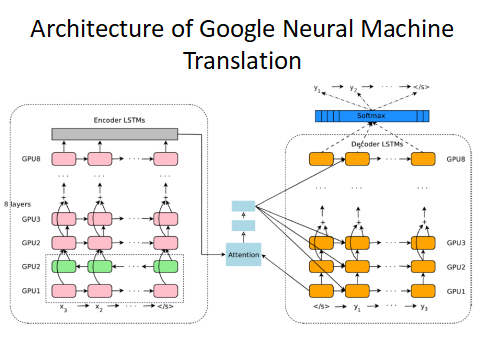
来自北大AI公开课李航:自然语言处理的现象与挑战
然而,这些人工智能系统通常需要大量的人工翻译的内容供计算机学习,而两篇新的论文则表明,可以开发一个不依赖平行文本的系统。
来自西班牙巴斯克大学(UPV)的计算机科学家 Mikel Artetxe 表示,你给一个人很多的中文书籍和阿拉伯语书籍,二者没有文字重复,在这种情况下,一个人学习将中文翻译成阿拉伯文很难,但计算机可能不会。
他们是用的是无监督学习方法。有监督学习可以理解为数据有标签,好比知道题目和答案,这意味着它会针对任何问题做出正确答案的尝试,人类会告诉它是否正确,并根据需要修改其活动。
在实际应用中,往往很难获取到数据标签,因此要选择无监督学习。例如,不管在哪种语言中,「桌子」和「椅子」经常一起使用。系统通过找到每种语言中这些关系,对其进行比较,就能理解哪些相关。
新论文中,提出的方法和此类似,还能翻译完整的句子。
论文中使用了两种策略:反向翻译」(Back Translation)和「去噪」(Denoising)。反向翻译是把一种语言写成的句子粗略翻译成另另一种语言,然后反向翻译回来,如果结果不相同,则对系统进行调整。去噪也是类似的过程,但不是来回翻译,而是向句子中添加单词等「噪声」。这些方法可以帮助机器更好地理解语言如何翻译。
这两个系统,一个是是 UPV 开发的,另一个是 Facebook 计算机科学家 Guillaume Lample。那么,如何评价者两种系统呢?二者选择比较英文和法文之间的双向翻译,其中包含了 3000 万个句子,这是两篇论文之间唯一能比较的结果。两者用来衡量翻译的准确性的评分均为 15 分,和谷歌翻译的 40 分相比要低,人工翻译则为 50 分。作者们均表示,这些系统能够通过半监督学习的方式得到改进,即有监督学习和无监督学习相结合。
此前,AlphaGo Zero 同样也不需要人类的经验,自行学会了棋谱。或许在未来,人工智能可以在很多领域「无师自通」,也能成为摆脱人类思维定势很好的方法。
责任编辑:双筒猎枪
头图来源:视觉中国返回搜狐,查看更多
责任编辑:

