简介
Raft 是一种通过日志复制来实现的一致性算法,提供了和Paxos 算法相同的功能和性能。
Raft 将一致性问题分解成了三个相对独立的子问题:
Leader选举:一个新的Leader需要被选举出来,当先存的Leader宕机的时候。
日志复制:Leader必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
安全性:选举安全性、Leader只附加原则、日志匹配原则、Leader完全特性、状态机安全特性等。
Leader选举
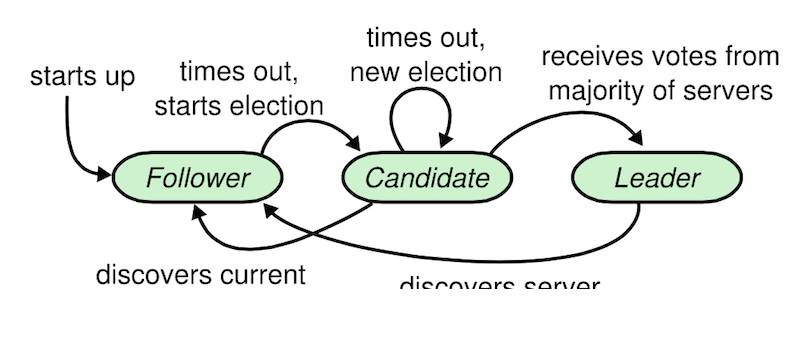
在Raft中,任何时候一个服务器可以扮演下面角色之一:
Leader:处理所有客户端交互,日志复制等,一般一次只有一个Leader。
Follower:类似选民,完全被动。
Candidate候选人: 类似Proposer律师,可以被选为一个新的Leader。
其中三种角色的变化如下:
Term:
在Raft中使用了一个可以理解为任期的概念,用Term作为一个周期,每个Term都是一个连续递增的编号,每一轮选举都是一个Term周期,在一个Term中只能产生一个Leader。
其中Term的变化流程:
Raft开始时所有Follower的Term为1,其中一个Follower逻辑时钟到期后转换为Candidate,Term加1这是Term为2,然后开始选举,这时候有几种情况会使Term发生改变:
1)如果当前Term为2的任期内没有选举出Leader或出现异常,则Term递增,开始新一任期选举。
2)当这轮Term为2的周期选举出Leader后,过后Leader宕掉了,然后其他Follower转为Candidate, Term递增,开始新一任期选举。
3)当Leader或Candidate发现自己的Term比别的Follower小时Leader或Candidate将转为Follower,Term递增。
4)当Follower的Term比别的Term小时Follower也将更新Term保持与其他Follower一致。
选举(Election)
Raft的选举由定时器来触发,每个节点的选举定时器时间都是不一样的,默认是0~1000ms之间,开始时状态都为Follower某个节点定时器触发选举后Term递增,状态由Follower转为Candidate,向其他节点发起RequestVote RPC请求,这时候有三种可能的情况发生:
1)该RequestVote请求接收到n/2+1(过半数)个节点的投票,从Candidate转为Leader,向其他节点发送heartBeat以保持Leader的正常运转。
2)在此期间如果收到其他节点发送过来的AppendEntries RPC请求,如该节点的Term大则当前节点转为Follower,否则保持Candidate拒绝该请求。
3)Election timeout发生则Term递增,重新发起选举。
在一个Term期间每个节点只能投票一次,所以当有多个Candidate存在时就会出现每个Candidate发起的选举都存在接收到的投票数都不过半的问题,这时每个Candidate都将Term递增、重启定时器并重新发起选举,由于每个节点中定时器的时间都是随机的,所以就不会多次存在有多个Candidate同时发起投票的问题。
有这么几种情况会发起选举:
1)Raft初次启动,不存在Leader,发起选举;
2)Leader宕机或Follower没有接收到Leader的heartBeat,发生选举超时从而发起选举;
所以在选举过程中,很关键一点就是选举定时器时间,由于这个时间是随机的,在0~1000ms之间,所以最新醒来的机器能够很快给其他机器发送投票,最终能很快达成一致,选出Leader。
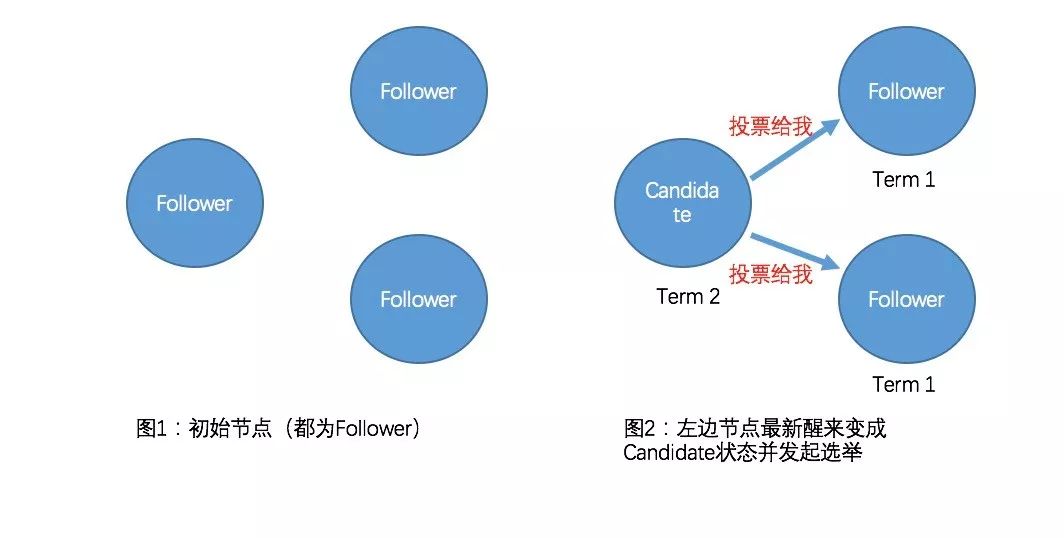
Leader Election1

Leader Election2
日志复制
当Leader被选出来后,就可以接受客户端发来的请求了(Leader是接收客户端请求的唯一载体),每个请求包含一条需要被replicated state machines执行的命令。Leader会把请求作为一个log entry append到本机日志中,然后给其它的server发AppendEntries RPC请求。当Leader确定一个log entry被安全复制了(大多数副本已经将该命令写入日志当中),就存储这条log entry到状态机中然后返回结果给客户端。如果某个Follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个Follower发AppendEntries RPC直到日志一致。
当一条日志是commited时,Leader才可以将它应用到状态机中。Raft保证一条commited的log entry已经持久化了并且会被所有的节点执行。
当一个新的Leader被选出来时,它的日志和其它的Follower的日志可能不一样,这个时候,就需要一个机制来保证日志的一致性。一个新Leader产生时,集群状态可能如下:

Replicated State Machines
最上面这个是新Leader,a~f是Follower,每个格子代表一条log entry,格子内的数字代表这个log entry是在哪个Term上产生的。
新Leader产生后,就以Leader上的log为准。其它的follower要么少了数据比如b,要么多了数据,比如d,要么既少了又多了数据,比如f。
要使得Flower的日志进入和自己一致的状态,Leader必须找到最后两者达成一致的地方。Leader针对每一个Flower维护了一个 nextIndex,表示Leader给各个Follower发送的下一条log entry在log中的index。当一个Leader刚成为Leader时,他初始化所有的 nextIndex 值为自己的最后一条日志的index加1。Leader给Follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,Follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给Leader回复拒绝消息,然后Leader则将nextIndex减1,再重复,直到AppendEntriesRPC消息被接收。
以Leader和b为例:
初始化时,Leader把nextIndex置为11,Leader给b发送AppendEntriesRPC(6,10),b在自己log的10号槽位中没有找到term_id为6的log entry。则给Leader回应一个拒绝消息。接着,Leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。循环下去,直到Leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。接收了消息。随后,Leader就可以从槽位5开始给b推送日志了。
安全性

注:Raft 在任何时候都保证以上的各个特性。
 返回搜狐,查看更多
返回搜狐,查看更多
责任编辑:

